In case you’re unaware , there’s a new crop of beta and public AI artwork generation technologies, that actually create some impressive looking artwork and imagery from relatively simple textual descriptions. Among the current crop of popular systems, these include: MidJourney, Dalle-E 2 , Stable Diffusion and many others…
What these systems allow users of all ability levels to do is describe the art with textual descriptions, the more descriptive the text and the more technical the details relating to the arts style, lighting, realism, compositions, framing , etc. the more refined the computer generated image you will get.
New York Times has a Good Article A.I.-Generated Art Is Already Transforming Creative Work about these systems and how creative professionals view them.
How does computer Generated AI Artwork, work?
The actual rendering of the artwork uses sophisticated AI algorithms and AI models , that you can read technical papers here DALL-E 2 (Hierarchical Text-Conditional Image Generation with CLIP Latents). and (Stable Diffusion description . Below is a nice video explaining some of the technical details behind the magic of DALLE-2 AI art engine. MidJourney uses similar diffusion technology.
But for the end user it just boils down to carefully and creative describing the type of artwork you want to render, and then fine tuning the rendered artwork with more precise descriptions.
A Few Amazing Images


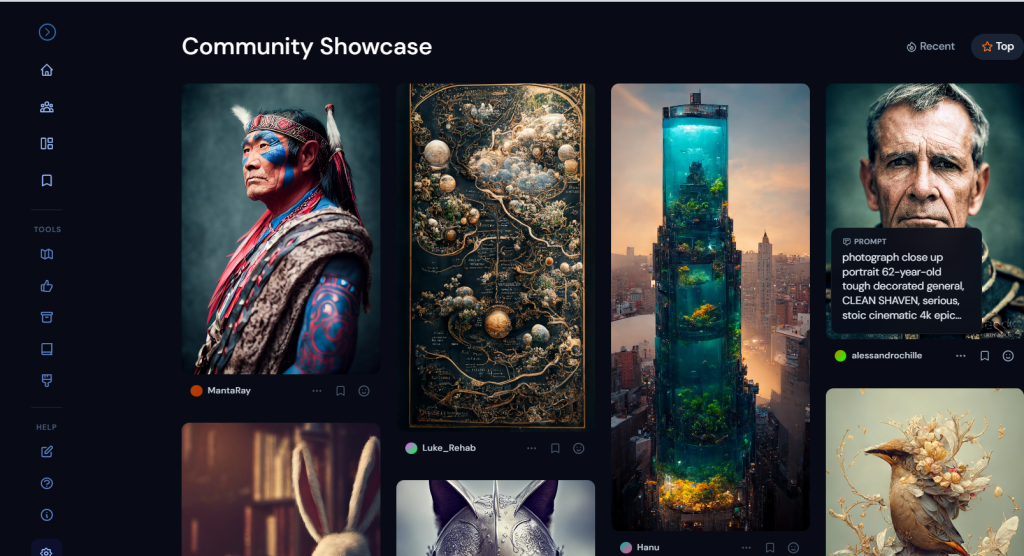
You can head over the various community showcase pages, to get a sense of the quality and variety of artwork and styles that the AI can generate. Some of the most impressive ones are usually the hyper-realistic photographic like renders of people, Here’s just a few examples I pulled from MidJourney’s community feed.
The firs one the decorated generated is a photo-realistic portrair created with the following prompt (photograph close up portrait 62-year-old tough decorated general, CLEAN SHAVEN, serious, stoic cinematic 4k epic detailed 4k epic detailed photograph shot on kodak detailed bokeh cinematic hbo dark moody)
This next one steampunk cat, octane render, hyper realistic, creates on interesting representation of what the computer thinks is a steampunk cat, the other terms octane render refers to the rendering style, and the are many, many styles available, these styles are familiar to digital artists who use them when the are creating artwork freehand and may be used to dictate the artistic style of the render.
The last example is just a simple landscape, using the prompt Vast Landscape, River, Mountains, Volumetric lighting, the image below was produced. Again this image is more typical of what a 3D or digital artist may create for a game of artwork. But of course the magic is this image was conjured up in minutes and allows the user the ability to further refine the AI’s creation.

A Few Limitations
Naturally , I wanted to try and render my own images, and most of these systems, are either in beta and by invite only or have a small subscription cost (to defer the expense of rendering and cpu time) , I chose midJourney’s $10/200 image renders, and began playing with all sorts of the interesting descriptions to try and become a textual Picasso or Monet. One of my renders is below.
This render was just quick and dirty prompt of new york city in 100 years , volumetric lighting in style of starr night , It didn’t come out exactly as I would have liked but for waiting 20 seconds, and costing me mere pennies its something that no digital artist would ever charge.
While some photos looked amazing or at least plausible interpretations of the prompt given, some did not for example I asked MidJourney for a shark jumping over waves and an airplane taking off in a storm, and neither of those images was particular convincing.

I noticed most of the high quality artwork showcased, is either images of portraits or closeups of people, or fanciful creations of illustrations of people, or animals or landscapes.
Whereas images of groups of people (2,3 or more) or groups of things such as an airport or marine port, or train station or football game, don’t tend to be rendered very accurately .
AI art generators Failing spectacularly

But not all prompts resulted in artistic masperpieces, more often than not spectatular misses happen..
For example when I asked it to render this.. view of many airplanes, parked at airport gates, with lots of activity on a BRIGHT blue cloudy day, volumetric lighting, hyperrealistic , I got the image here which is a complete fail, there are no airplanes, not gates, and the clouds seem to be the center of the action and not a supporting elements.
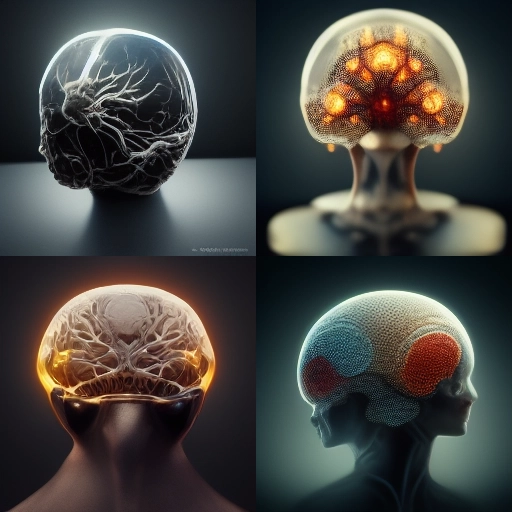

Next I tried asking it to draw me a very accurate and detailed representation of the human brain. This should have resulted in what we normally see rendered as the human brain but instead this was “rendered”
My guess is the training data for the various AI models coupled with the diffusion process.. is easier to annotate for individual elements (like people, animals, landscapes) than for complex groupings of those things.. So when you try to render something like a two tennis players volleying back and forth , you’ll get very bizarre renders.. But I have no doubt this will improve with time.
Artwork going forward, and the role of (human) digital Artists
Midjourney recently gathered some controversy as one of its pieces won a recent art contest. The piece Jason Allen entered the artwork titled “Theatre d’Opera Spatial” in the “Digital Arts / Digitally-Manipulated Photography” category of the Colorado State Fair fine arts competition but created the piece using a popular text-to-image AI generator named Midjourney..

This of course brings us to the big question the elephant in the room, as with many AI technologies, what happens to all those digital artists who slaved to hone their artistic craft, what about al those digital art jobs for games, books, movies etc.. Well I think the role of the artist now changes from one who manually creates the artwork, to one, who learns how to paint with words, as opposed to with pixels . ultimately the artist will still be needed to fine tune the final piece or to customize some part that the AI doesn’t understand how to do. Plus ultimately people hiring artists simply don’t want to be bothered learning the complexities of the textual descriptions, and will gladly pay an expert to describe to the computer what to do.